Data-310
- Plots describing input preprocessing step:
Metro:
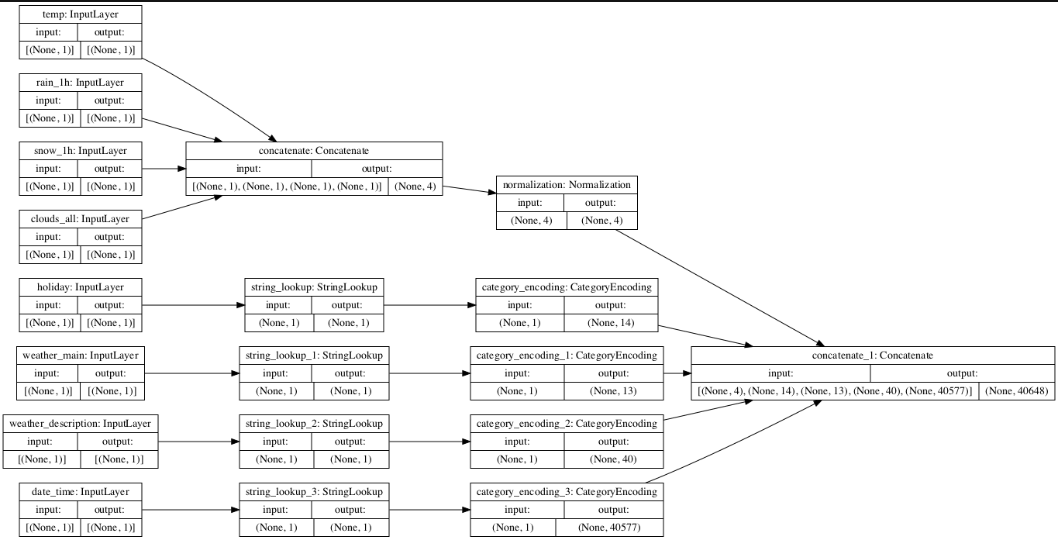 Iris:
Iris:
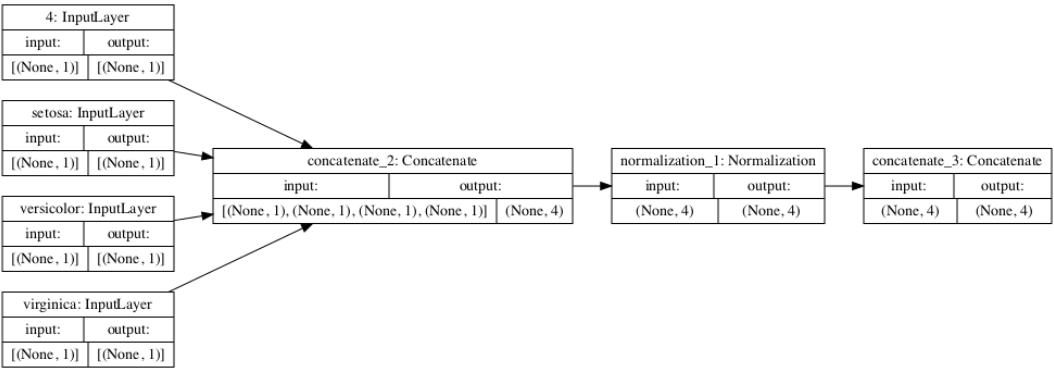
-
Describe the plot of each model for the two dataset preprocessing steps.
a. What does each box in the illustration represent?
The boxes represent a preprocessing layer.
b. Are there different paths towards the final concatenation step?
For metro, yes: the first four variables take a different path including normalization, while the last four variables do not go through this step. This is because the first four variables are continuous. In the Iris dataset every variable is continuous, so they all take the same path.
c. What is occurring at each step and why is it necessary to execute before fitting your model?
At the first step, numerical data are concatenated and then normalized in the second step. Categorical data is converted to numerical data in the first and second steps, and then in the third step the numerical and categorical data are concatenated. This is necessary before fitting the model because all the data used must be in a similar range and in the same format.
-
Train each model and produce the output (not necessary to validate or test).
Metro:
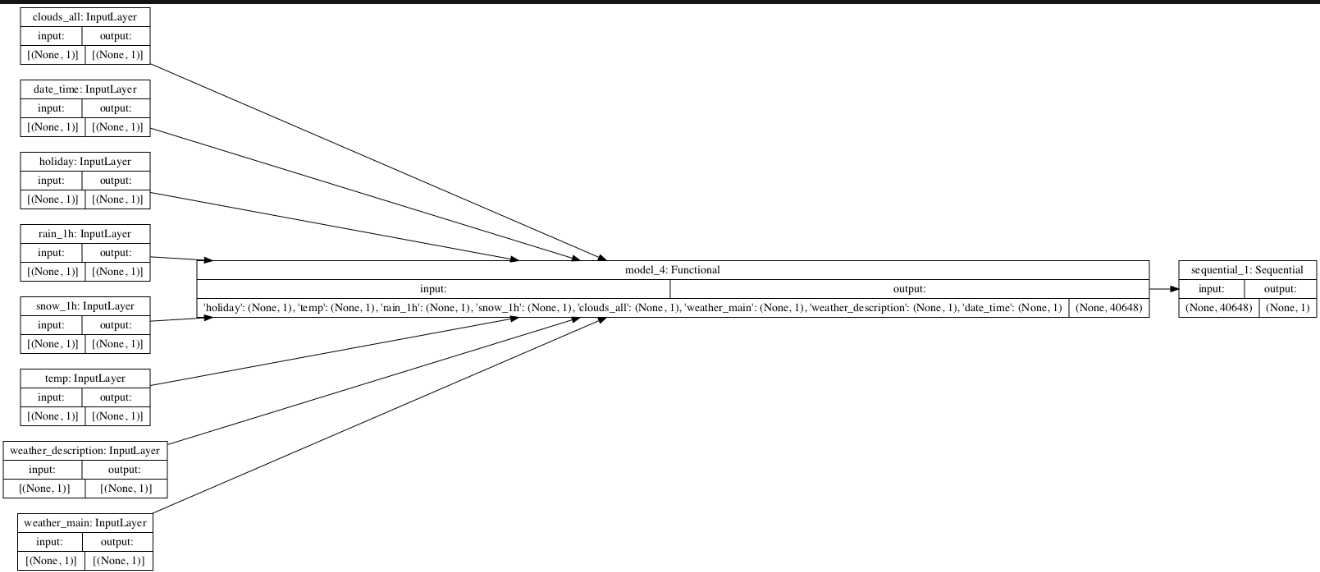 Iris:
Iris:
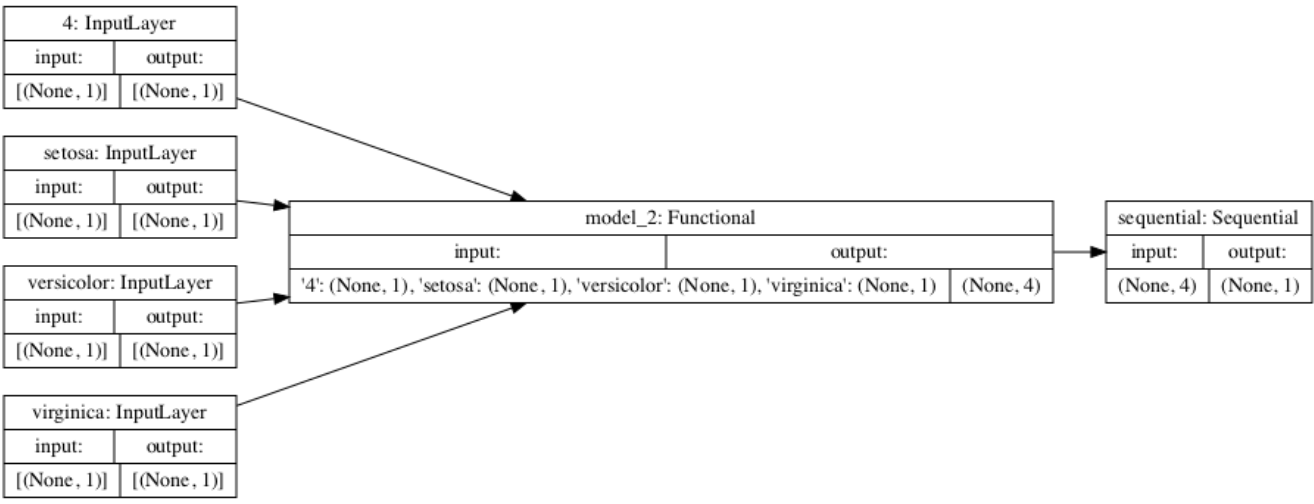
-
Describe the model output from both the metro traffic interstate dataset and the iris flowers dataset.
a. What is the target for each dataset?
The target for the metro dataset is traffic volume, and the target for the iris dataset is a number between 1-4 which indicates the flower type.
b. How would you assess the accuracy of each model?
I assessed the accuracy of the metro dataset through loss over epochs, and there was a lot of loss. The loss was in the thousands, and because of that I thought a graph wouldn’t be useful since there’s an absurd amount of loss, showing the model is not very accurate. I assessed the accuracy of the iris dataset also through loss over epochs. It did slightly better than the metro dataset, probably because it has less features. However, my loss values were negative and I’m not exactly sure why or what that means.
c. Are you using a different metric for each one? Why is this so?
Yes, because the metro dataset has mixed data types, and the iris dataset does not.