Data-310
#Preprocessing
- Pick 3 images:
- index 100
- index 101
- index 102
- index 100
#Make Predictions
-
What does the array represent?
The following is the predictions array for the 10th image. The numbers represent the model’s confidence in the image’s correlation to each of the 10 labels. The higher the number, the higher the % of confidence.
array([3.8757089e-06, 3.9885109e-08, 4.6757638e-02, 1.8446302e-08, 9.4626385e-01, 9.9321662e-09, 6.9739721e-03, 2.2785258e-09, 4.0543335e-07, 1.8399857e-07], dtype=float32) -
How were softmax and argmax applied?
Softmax converted output numbers from our model to probabilites we can interpret through first calculating exponentials for each number, summing the exponentials, and dividing each exponential by the sum.
Argmax located the index in the predictions array with the highest number and therefore highest probability.
-
Does the np.argmax output match the label from test_labels?
Yes: both were 4
#Verify predictions
-
Plot 2 more images and include graph of predicted label in addition to image
- index 200
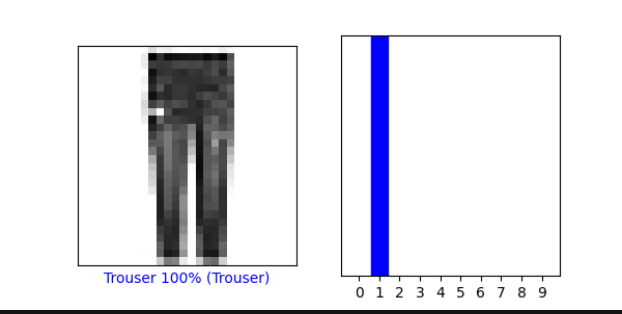 2.index 201
2.index 201
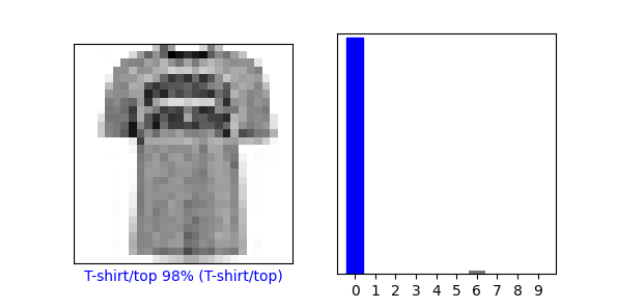
- index 200
#Use the trained model
-
New image, predict. Does predicted value match test label?
No.
-
Why didn’t use softmax but argmax?
When we made the probability model, we already converted logits to probabilities and thus don’t need to again.
#Mnist
- Plot of 25 handwritten numbers

-
Accuracy of training dataset
0.997
-
Accuracy of test dataset
0.9786
- Plot 2 images, graph of predicted label + image
- index 200
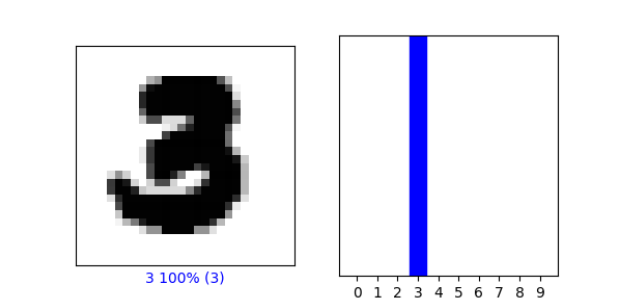
- index 201
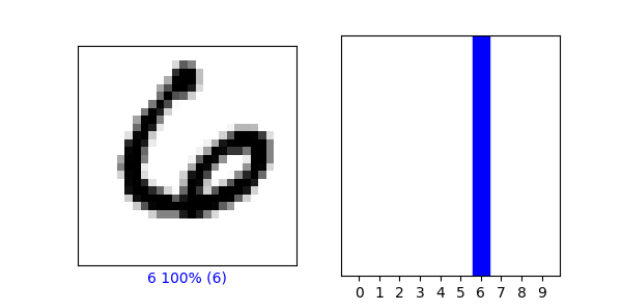
- index 200
#Comparison
-
Which of 2 models is most accurate?
The MNIST dataset is most accurate.
-
Why?
The MNIST training and testing dataset accuracy were more accurate (higher) than the fashion_MNIST’s training and testing accuracy.